highlight: atom-one-dark theme: vuepress--- 一起养成写作习惯!这是我参与「掘金日新计划 · 4 月更文挑战」的第7天,点击查看活动详情 (opens new window)。
大家好~我是
米洛!
我正在从0到1打造一个开源的接口测试平台, 也在编写一套与之对应的教程,希望大家多多支持。
欢迎关注我的公众号米洛的测开日记,一起交流学习!
# 回顾
上一节我们把请求地址给优化了一顿,今天群里的一个测友给了点建议,说我查询个人信息的接口暴露的字段太多了。啥密码、邮箱、手机都给展示了出来,那么这一节我们专门针对这个,来改造一番。
# 现有的Response
我们之前封装过一个PityResponse,里面有一些基础功能,咱们看看:
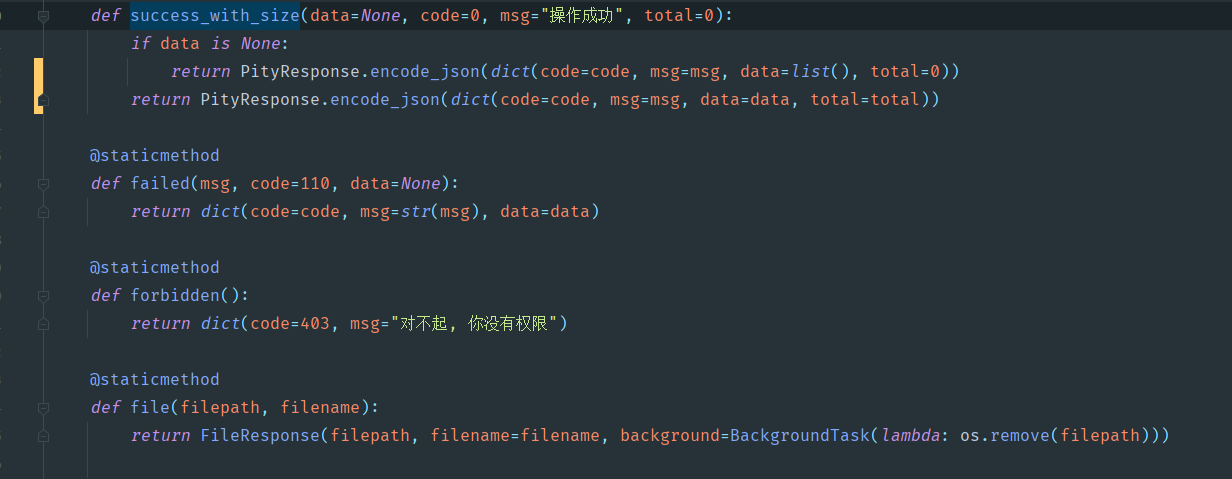
可以看到,我们就是包了一层,把原先的dict给包装了起来,新增了一些默认参数比如msg和code,定义了不同的方法,等于是简化了api。但我们其实一直有个很大的弊端,往下看:

我们有个model_to_list的方法,里面的操作呢,就是去遍历数组,再把sqlalchemy的对象转换为字典。也就是有2层for循环,第一层是数组的循环,第二层是字典的key-value。
第二层的话,由于一个对象一般不会有很多字段,有也不会超过100个那么多,所以还是可以接受的。但如果list有1000条数据,比如操作记录啊啥的分分钟过1000(不考虑分页的情况下),那这样序列化的速度就会明显变慢。
所以今天我们就顺势而为,解决这个问题。
# json_encoder
之所以我自己写一个model_to_dict的方法,是因为我对时间格式有着洁癖,我希望的时间格式是: 2022-04-06 12:11:11,如果有2022-04-06T12:11:11,我都会觉得辣眼睛(焦躁)。
那有没有更简单的办法呢?肯定有的啦,fastapi作为一个新生代的框架,这点东西还是能想到的。
我们来看官网给的例子:
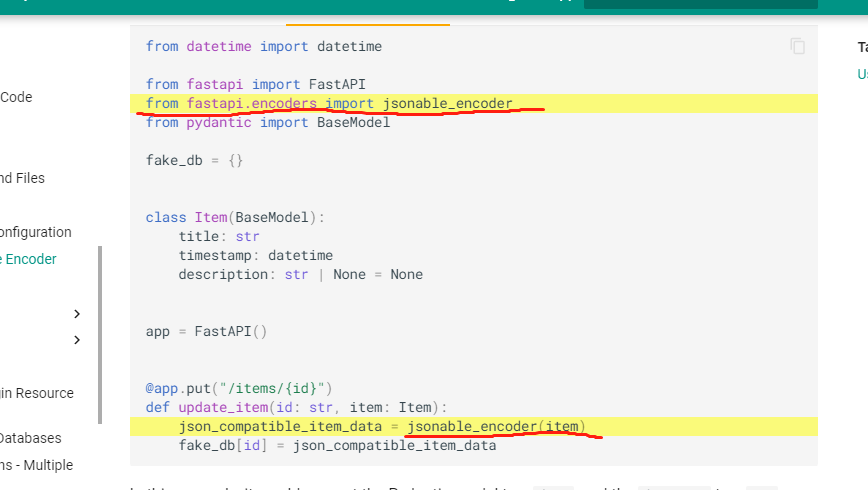
官网就是官网,还是一如既往的简洁(粗糙)。
简单的说,就是引入json_encoder方法,接着调用它,传入你要序列化的数据(字典,pydantic的model,sqlalchemy的model都可以),最后就会如意如意按你心意进行序列化了。
# 熟悉它的api
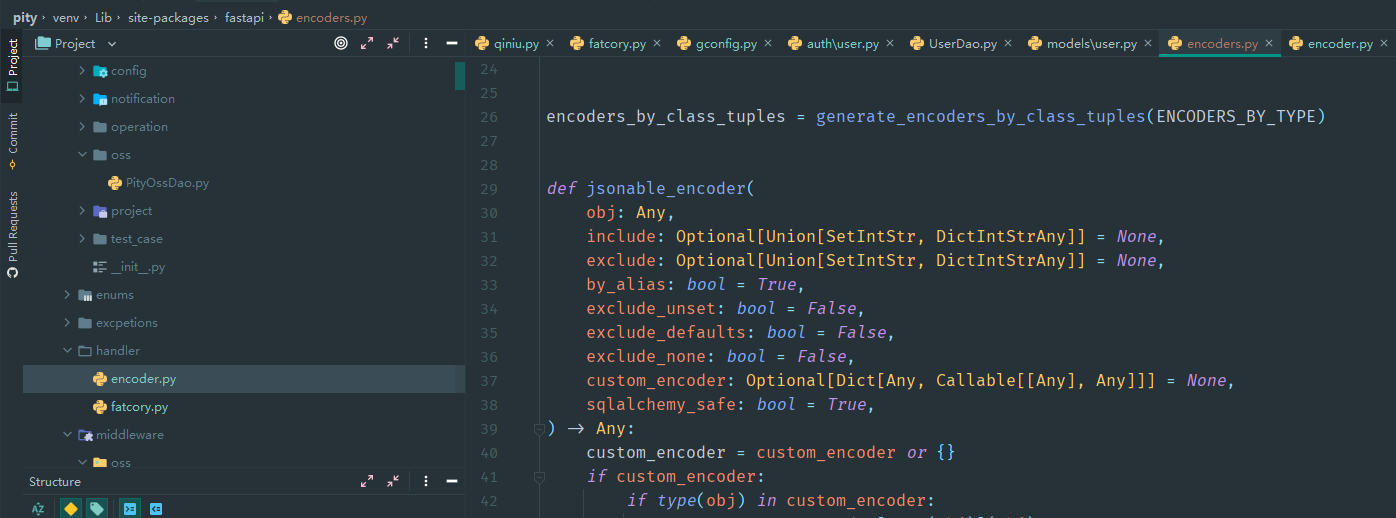
参数很多,但没啥描述!
根据语义,我们可以推断出,obj就是要序列化的对象,include就是要包括的字段(不传就是所有咯),exclude是不包含的字段,记得我们前面的需求吗?我们需要排除password等字段。
custom_encoder这个参数就比较过分了,完美实现我们对时间格式的要求,它的作用是(认真听):
接受一个字典,key呢,是对应的类型,value是一个方法,方法的参数是属性的value,返回值是你要变成的value。
举个例子: 我们的object里面有个datetime类型,所以我们可以这么写:
jsonable_encoder(data, custom_encoder={
datetime: lambda x: x.strftime("%Y-%m-%d %H:%M:%S")
})
2
3
# 开始改造
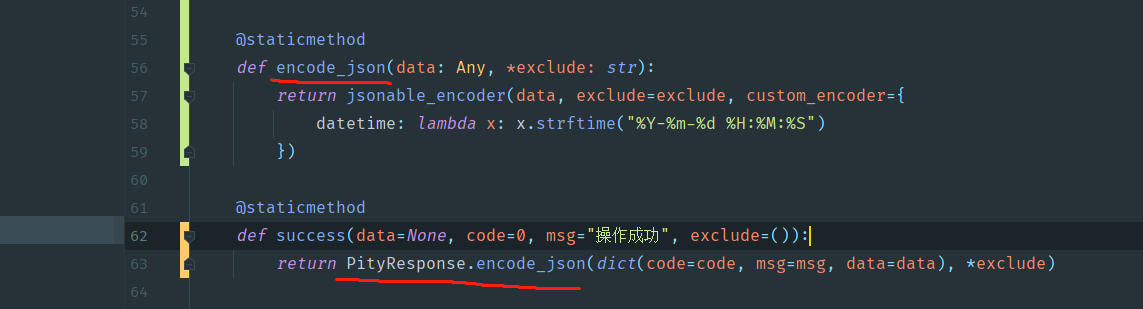
我们定义一个encode_json的方法,传入exclude和custom_encoder,接着套到success里面,以往我们这样的api,就可以进行替换了.
- 替换前(真的**)
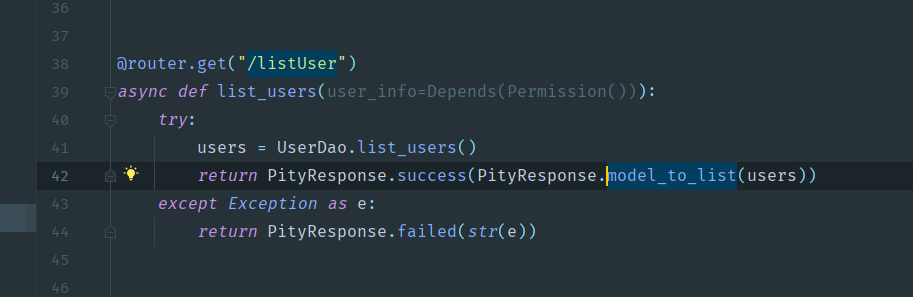
- 替换后
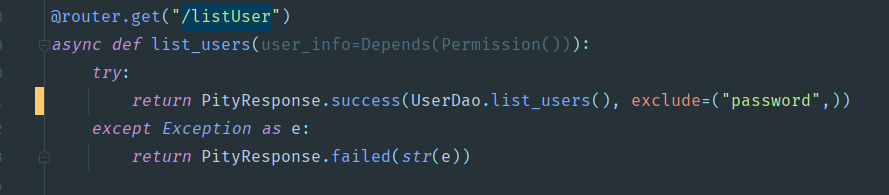
清爽一点点,还增加了排除的字段。
# 看看效果
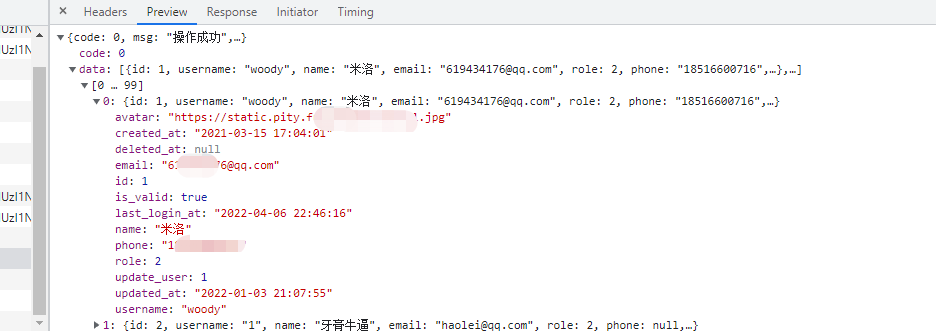
密码无了,嘿嘿,搞定。
# Bonus
其实吧,这里面有坑,如果你跟着写下来的话会发现exclude不会真的生效,因为json_encoder的源码只有第一层是接受了exclude参数的,递归的部分是没有的。那么怎么解决呢?
还是看看pity源代码吧~